
 Greetings friends, for a long time I have found in more and more places the need of IT Departments to offer the backup as a service internally to the rest of the departments.
Greetings friends, for a long time I have found in more and more places the need of IT Departments to offer the backup as a service internally to the rest of the departments.
This means that the IT and Backup managers create the entire infrastructure and backup possibilities, and it is the different managers of each application or group of applications who are responsible.
Create an SLA policy plan according to our business
The first thing we will have to do is sit down and create these SLA plans, according to the needs and obligations of our company. For example, let’s imagine that we have three different levels of protection for our environment.
BACKUP-SLA-30-24
This policy, probably one of the most typical in any company, is to make a backup every 24 hours, with retention for 30 days. In the repository, we would have something like this: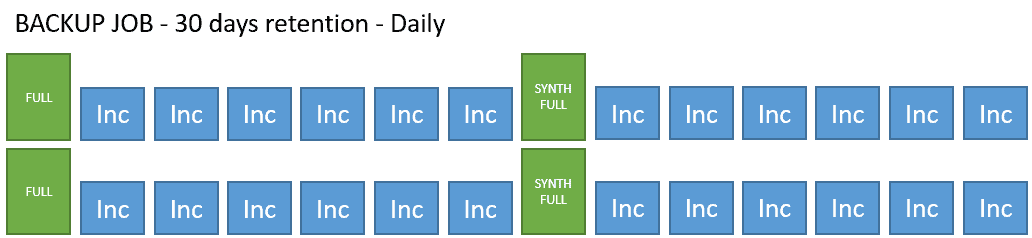 Note: The theme of the synthetic full is something I recommend, but it is optional, they could be Active Full.
Note: The theme of the synthetic full is something I recommend, but it is optional, they could be Active Full.
BACKUP-SLA-30-06
This policy performs a backup every 6 hours, with a 30-day hold. In the repository we would have something like this:
Note: The theme of the synthetic full is something I recommend, but it’s optional, they could be Active Full, being every 6 hours, I would recommend a synthetic to compact everything every night, hence the synthetic every 4 points.
BACKUP-SLA-30-01
This policy, which we would consider our most critical level, is to perform an hourly backup, with a 30-day hold. In the repository we would have something like this: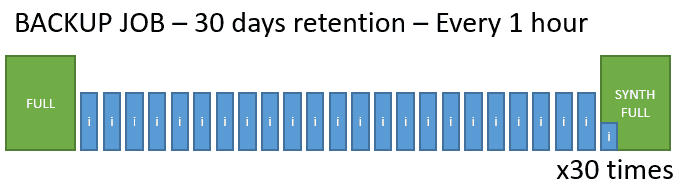 Note: The theme of the synthetic full is something that I recommend, but it is optional, they could be Active Full, being every hour, I would recommend a synthetic to compact everything every night, hence the synthetic every 24 points.
Note: The theme of the synthetic full is something that I recommend, but it is optional, they could be Active Full, being every hour, I would recommend a synthetic to compact everything every night, hence the synthetic every 24 points.
Topology of a backup environment based on SLA policies
The biggest advantage that this way of protecting the environment has is that we delegate completely the responsibility of the machines to protect, with the retention that is needed to those responsible for such systems, the design for a medium-large environment could be like that: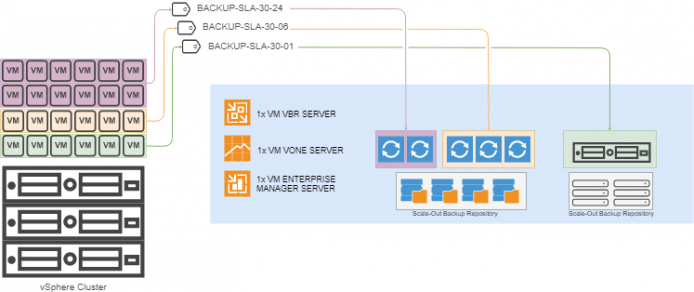 In which we find that a single VM server from Veeam Backup & Replication, and different proxies dedicated to each tag is enough. In the most demanding case, which is the backup of every hour, we will have to have a physical server connected to the production SAN, connected to a high-performance appliance type Repository or to fast disks, or a RAID 10 or 60.
In which we find that a single VM server from Veeam Backup & Replication, and different proxies dedicated to each tag is enough. In the most demanding case, which is the backup of every hour, we will have to have a physical server connected to the production SAN, connected to a high-performance appliance type Repository or to fast disks, or a RAID 10 or 60.
Optionally we can have VMs for Enterprise Manager and another for Veeam ONE
Veeam Backup & Replication’s scalable architecture and infrastructure design
To design service like this, we can’t use a virtual proxy with a backup repository and think that we already have everything ready (by proxy we can, but I don’t recommend it).
To design correctly the environment we are going to have several elements in mind:
- The total number of concurrent tasks we want to assign at first
- The total number of extents that will be part of our Scale-Out Backup Repository
- The frequency with which the tasks are executed, against more frequent less working window we have with what more proxies we will have to put to process more concurrent tasks and the repositories will have to have more bandwidth (better disks and better connections)
Let’s think we have several generic servers with storage such as Backup Repositories.
BACKUP-SLA-30-24
This means, for example, that to service say, 100VMs with 2 VMDK (2 disks) each with an average size of 300GB for each VM in total every 24 hours, we could design something like the following: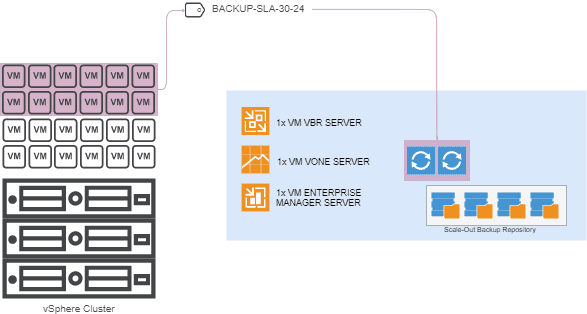 Which in numbers would be:
Which in numbers would be:
- 2x Virtual Proxy
- 4vCPU
- 8GB RAM
- VMXNET3 and PVSCSI
- 80GB for OS (Windows Server 2016/2019)
- Our Backup Repository should have the following resources (more or less):
- 4 Cores or more
- 10GB RAM
- Full MB/s copy: 200.25
- Incremental copy MB/s: 20.02
Nothing too big or complex, as they are simple copies.
BACKUP-SLA-30-06
This means, for example, that to service say, 50VMs with 2 VMDK (2 disks) each with an average size of 300GB for each VM in total every 24 hours, we could design something like the following: Which in numbers would be:
Which in numbers would be:
- 3x Virtual Proxy
- 4vCPU
- 8GB RAM
- VMXNET3 and PVSCSI
- 80GB for OS (Windows Server 2016/2019)
- Our Backup Repository should have the following resources (more or less):
- 6 Cores or more
- 14GB RAM
- Full MB/s copy: 400.50
- Incremental copy MB/s: 40.05
Here the number of proxies is already increasing, as well as the bandwidth that the Backup Repository has to give us.
BACKUP-SLA-30-01
Our most critical applications, we most likely want to use SAN Transport Mode (require a physical proxy) AND Backup from Storage Snapshots whenever possible.
For example to service say, 20VMs with 2 VMDK (2 disks) each with an average size of 300GB per VM in total every 24 hours, we could design something like the following: Which in numbers would be:
Which in numbers would be:
- Our Proxy, which is physical this time requires the following:
- 32 Cores or more
- 64GB RAM or more preferably
- VMXNET3 and PVSCSI
- 80GB for OS (Windows Server 2016/2019)
- Our Backup Repository should have the following resources (more or less):
- 20 Cores or more
- 128GB of RAM or more
- Full MB/s copy: 961.19
- Incremental copy MB/s: 96.12
As it is the most resource-consuming, in this case, we would be talking about solid disks if possible, or with a RAID 10, 60, or similar to accelerate the writing, in addition, the physical proxy has to be powerful to execute as many concurrent tasks as possible, better.
How to Create our SLA Policy in VMware vSphere
From vSphere, we’ll go to the menu, Tags & Custom Attributes: In Categories, we’ll create a new one:
In Categories, we’ll create a new one: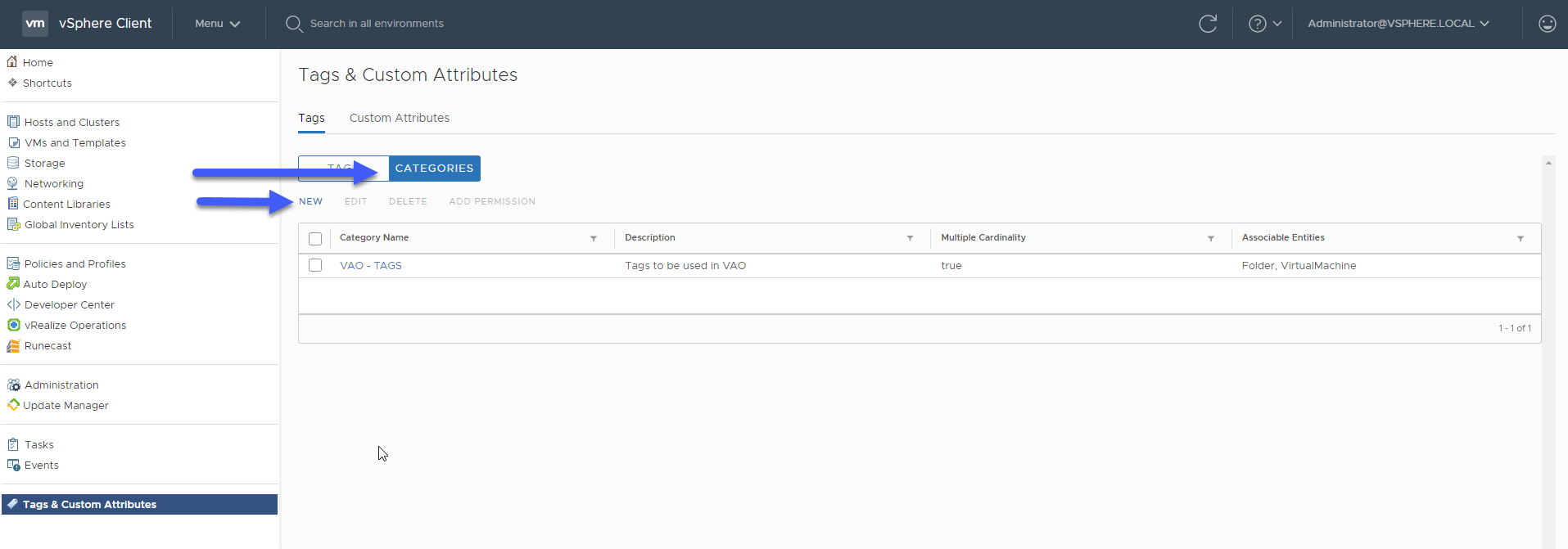 We’ll call this category BACKUP, besides introducing a description for it, and select where this category can be applied, in my case only in some components:
We’ll call this category BACKUP, besides introducing a description for it, and select where this category can be applied, in my case only in some components: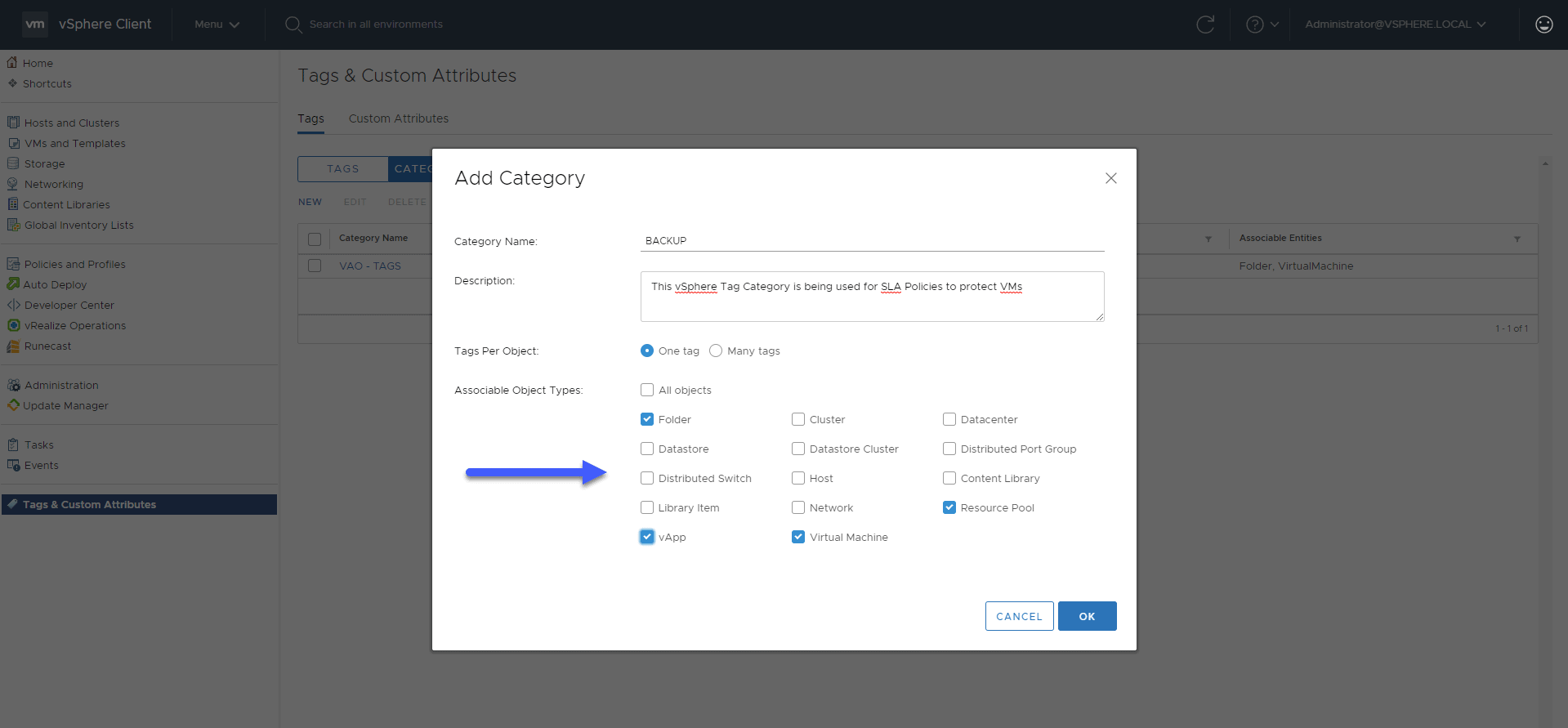 Back to the Tags section, we will create the corresponding ones:
Back to the Tags section, we will create the corresponding ones: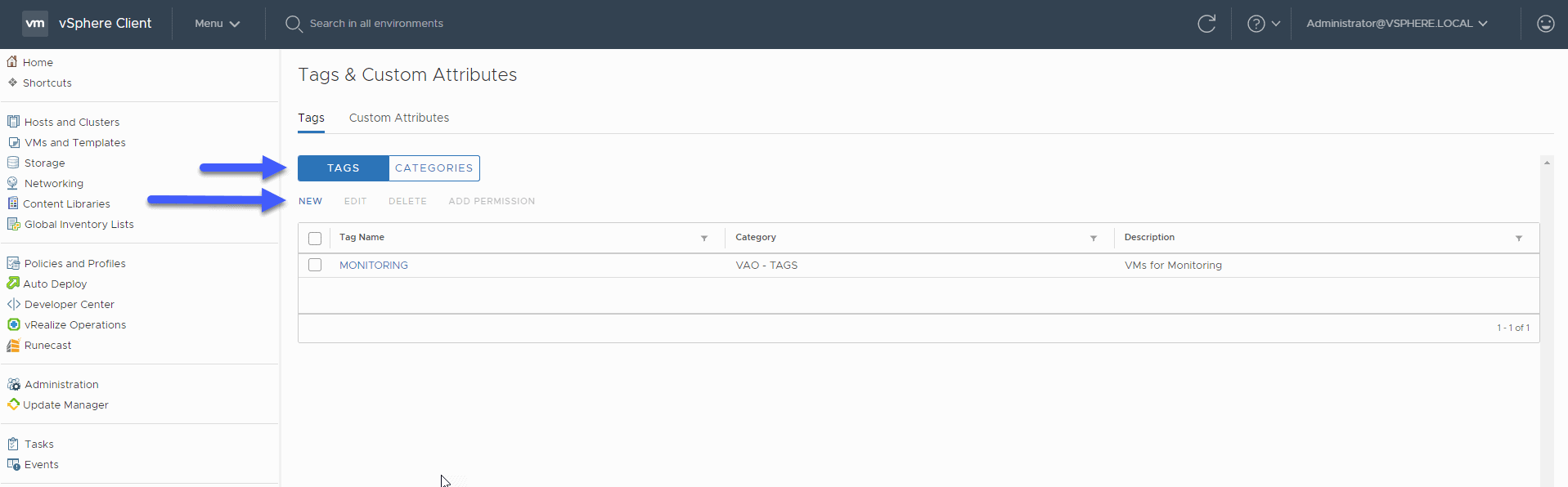
BACKUP-SLA-30-24 (30 days of retention, every 24 hours)
For example, we will create our first Tag that will be used as an SLA policy to create backups every 24 hours, with 30 restore points: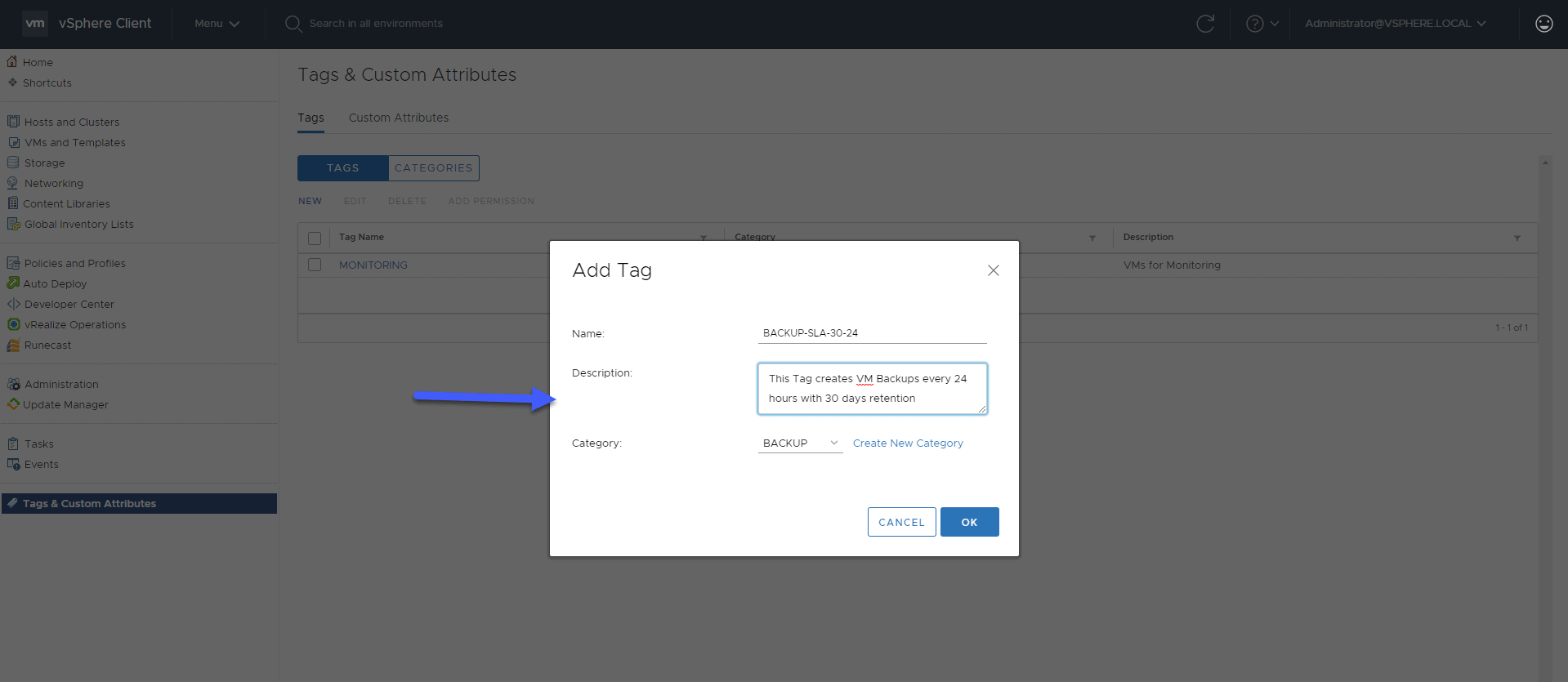
BACKUP-SLA-30-06 (30 days of retention, every 6 hours)
We will now create the second tag that will be used as an SLA policy to create backups every 6 hours, with 30 restore points: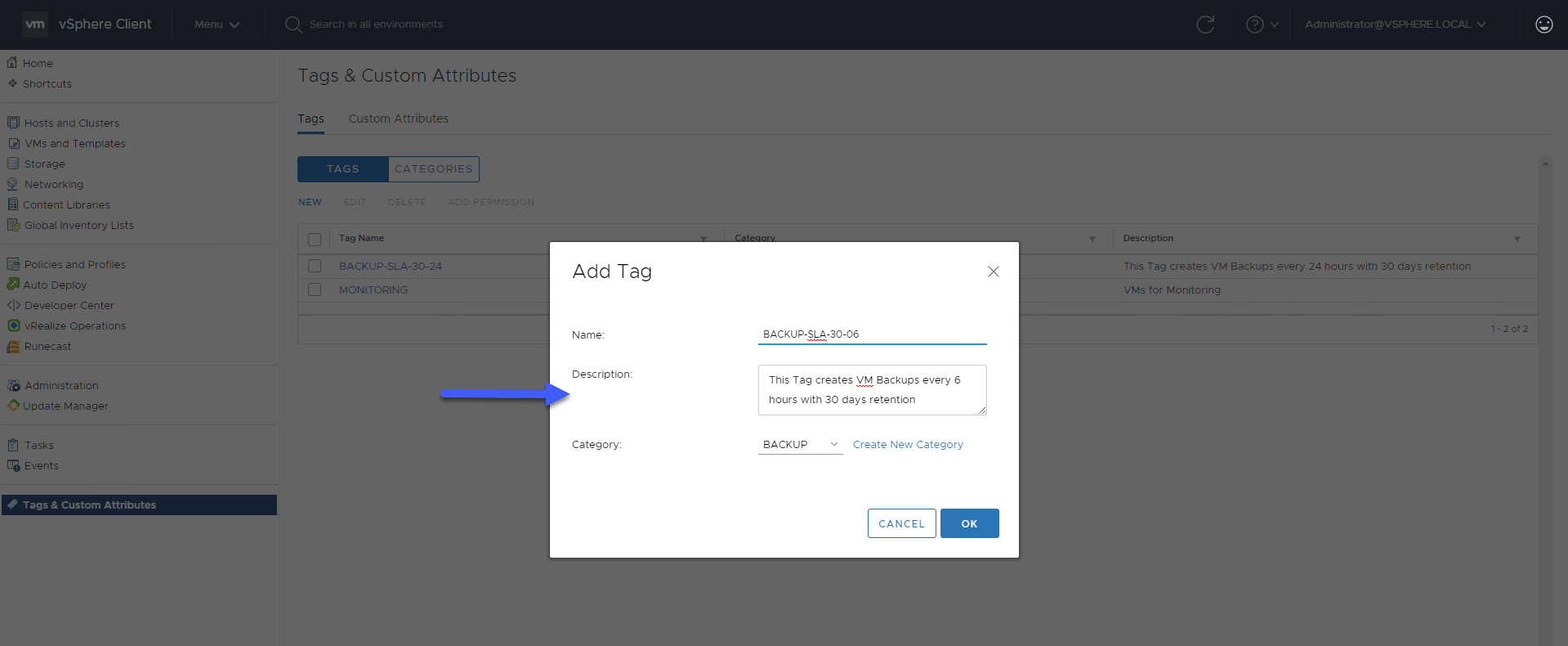
BACKUP-SLA-30-01 (30 days of retention, every 1 hour)
Finally, the last tag that will be used as SLA policy to create backups every 1 hour, with 30 restore points: 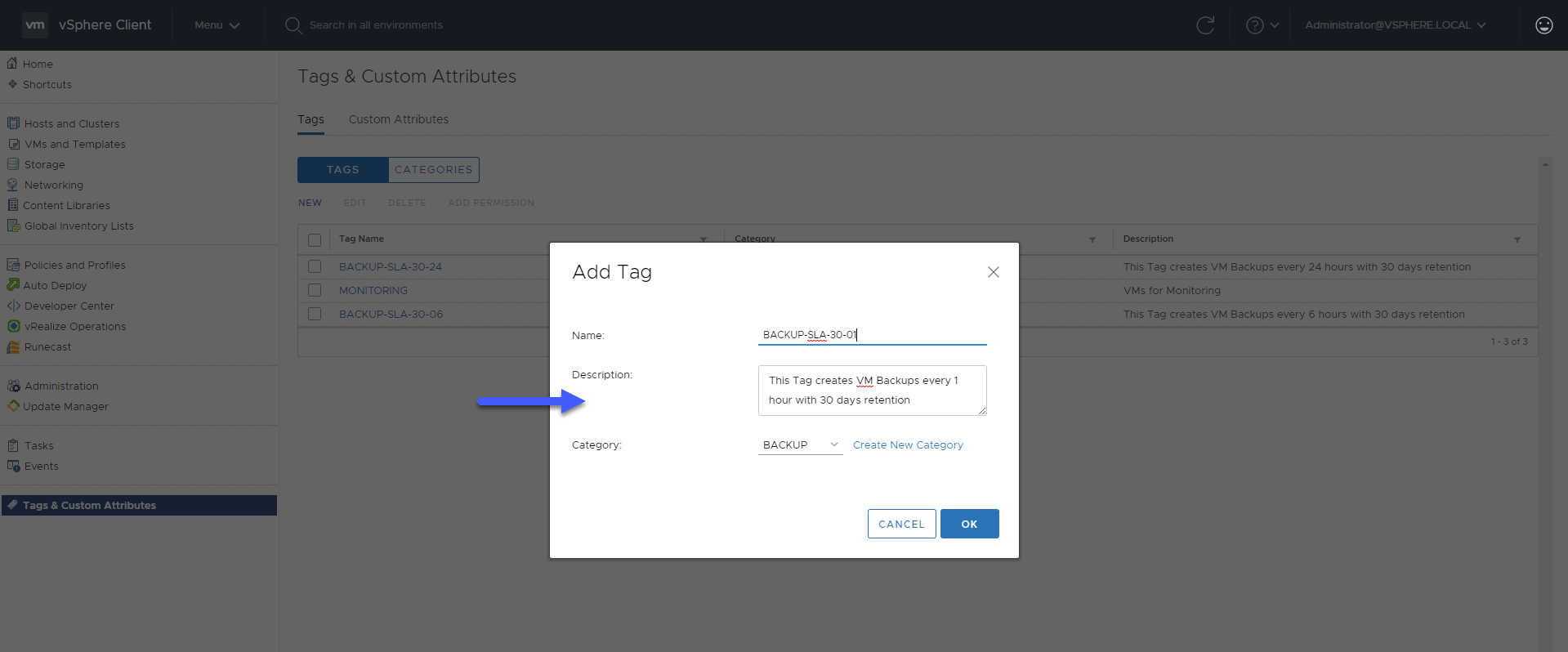 That’s all for now in this first part of this blog series about SLA policies to create backups, I leave you with the complete series:
That’s all for now in this first part of this blog series about SLA policies to create backups, I leave you with the complete series:
- Veeam: How to Design and Implement a Backup System Based on SLA Policies – Part I – Design, Architecture, and Tagging in vSphere
- Veeam: How to Design and Implement a Policy-Based Backup System – Part II – Creating the Policies in Veeam Backup & Replication
- Veeam: How to Design and Deploy a Backup System Based on SLA Policies – Part III – Assigning vSphere Tags to Application Groups
- Veeam: How to Design and Implement a Backup System Based on SLA Policies – Part IV – Quick Overview and Reporting of Backup Policies
- Veeam: How to design and implement a policy-based SLA backup system – Part V – Monitoring the Veeam Backup & Replication environment with Veeam ONE
Leave a Reply