
 Greetings everyone, a few weeks ago I’ve discussed the importance, and use-cases of using on-prem object storage with QNAP QuObjects, which is great for a quick homelab, or small repositories.
Greetings everyone, a few weeks ago I’ve discussed the importance, and use-cases of using on-prem object storage with QNAP QuObjects, which is great for a quick homelab, or small repositories.
When we speak about on-prem Object Storage, focused on the Enterprise, or big Service Providers, we will need a robust solution like Cloudian.
Quick Diagram about Where Cloudian Fits
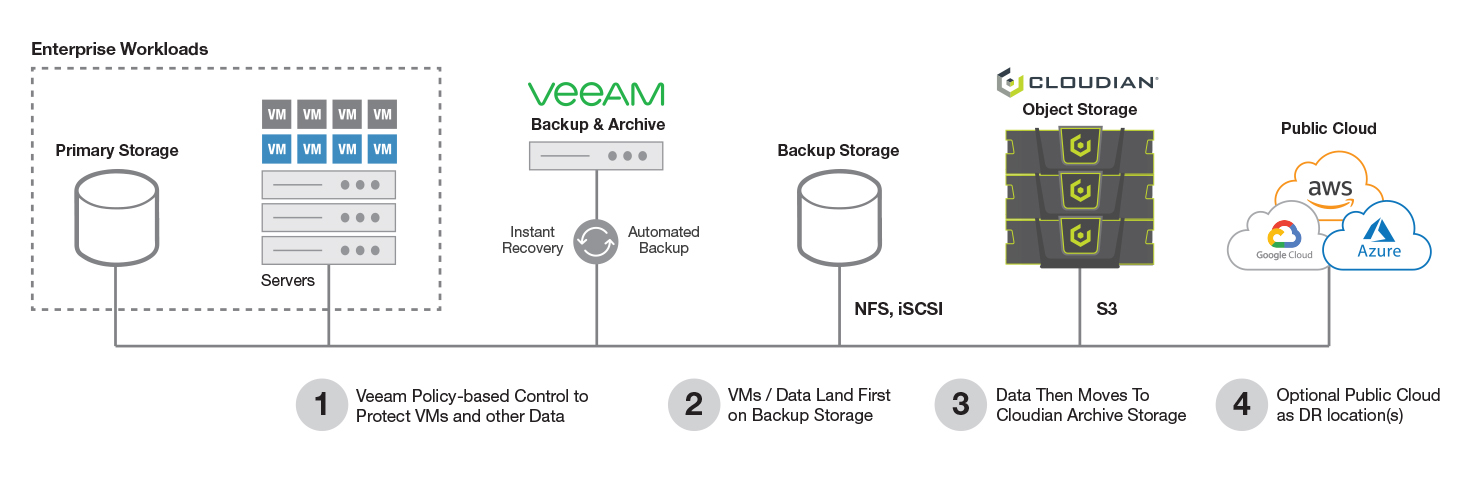
As said before, there are Companies that due to regulations, or even just to keep costs under control, these Customers prefer Object Storage on-prem. The main use-case of this usually is to have an air-gap different from traditional storage, the diagram could look something like this:
- We have at the left our Primary Storage, and the Production workloads there, physical, virtual, Workstations, etc.
- Then, we introduce the Backup layer, Veeam Backup and Replication, that of course, allows us to trigger Instant Recovery, Automated Backup, etc.
- Veeam Backup and Replication require Storage to save the Backup, I do 100% recommend Linux Repositories with Immutability, but it does support as well any Windows Server with ReFS, NFS, iSCSI, etc.
- Now, the new layer, an additional copy, our air-gap, the Cloudian Object Storage. We can configure our Scale-Out Backup Repositories to send COPY, and even MOVE as well, and keep the immutability on these Buckets.
- Finally, and completely optional, we can even have a third copy of the data into Public Cloud, but probably not ideal for those use cases to keep data on-prem, or cost-prediction desire.
 Cloudian HyperStore is the technology that Cloudian deploys on Customers Datacenter to present the different Buckets. Cloudian has extra measurements to protect the data that hosts, these are the next ones:
Cloudian HyperStore is the technology that Cloudian deploys on Customers Datacenter to present the different Buckets. Cloudian has extra measurements to protect the data that hosts, these are the next ones:
- Replication — with replication, a configurable number of copies of each data object are maintained in the system, and each copy is stored on a different node. For example, with 3X replication, 3 copies of each object are stored, with each copy on a different node.
- Erasure Coding — with erasure coding, each object is encoded into a configurable number (known as the “k” value) of data fragments plus a configurable number (the “m” value) of redundant parity fragments. Each fragment is stored on a different node, and the object can be decoded from any “k” number of fragments. For example, in a 4:2 erasure coding configuration (4 data fragments plus 2 parity fragments), each object is encoded into a total of 6 fragments which are stored on 6 different nodes, and the object can be decoded and read so long as any 4 of those 6 fragments are available.
Supported erasure coding configurations
Cloudian HyperStore supports three erasure coding configurations. This will give us the peace of mind and security that we need:
- 2+1 — each object will be encoded into 2 data fragments plus 1 parity fragment, with each fragment stored on a different node. Objects can be read so long as any 2 of the 3 fragments are available.
- 4+2 — each object will be encoded into 4 data fragments plus 2 parity fragments, with each fragment stored on a different node. Objects can be read so long as any 4 of the 6 fragments are available.
- 9+3 — each object will be encoded into 9 data fragments plus 3 parity fragments, with each fragment stored on a different node. Objects can be read so long as any 9 of the 12 fragments are available.
How-To Deploy HyperStore v7.x on top of VMware vSphere v7.x – on comfortable video
I am aware that this procedure is not that easy, really, it just takes you around 30 minutes, or a bit more, so I’ve decided to put a guide about how to do it, on top of VMware, with a luxury of details, comments, etc. Hope you like it:
I’ve used the HyperStore Admin Guide, which contains a lot of information, take a look.
- https://s3-eu-1.demo1.cloudian.eu/downloads/HyperStore/7/7.2.4/doc/HyperStorePDFManuals/HyperStoreAdminGuide_v-7.2.4.pdf
- https://s3-eu-1.demo1.cloudian.eu/downloads/HyperStore/7/7.2.4/doc/HyperStorePDFManuals/HyperStoreInstallGuide_v-7.2.4.pdf
I will not include the step by step on images this time, as there are lot of screenshots, plus the official Cloudian Guide is detailed enough.
Leave a Reply